Understanding Overfitting and Underfitting in Machine Learning
Written on
Chapter 1: Introduction to Overfitting and Underfitting
Machine learning models strive to identify patterns from given data and make accurate predictions on data they haven't encountered before. However, finding the right equilibrium between the complexity of the model and its performance can be quite difficult. Overfitting and underfitting are two frequent challenges in machine learning that arise when a model's performance diverges from the intended goal. This section will explore these concepts and discuss methods to counteract them.
Section 1.1: Overfitting: When a Model Learns Too Much
Overfitting occurs when a model excessively learns from the training data, capturing noise and unnecessary details. In essence, the model aligns too closely with the training data, making it challenging to generalize to new, unseen instances. Nonparametric and nonlinear models, which offer more flexibility in learning target functions, are particularly prone to overfitting. Many nonparametric machine learning algorithms incorporate parameters or techniques to restrict the amount of detail the model acquires.
Take decision trees, for example; they are a nonparametric algorithm that can easily overfit the training data due to their flexibility. This issue can be mitigated by pruning the tree after training, which removes some of the excessive details it has learned. Consider the analogy of memorizing a textbook rather than understanding the concepts; while you may excel at identical questions, you might struggle with new ones.
Causes of Overfitting:
- High Model Complexity: Complex models like deep neural networks have a greater ability to memorize data, increasing the risk of overfitting.
- Insufficient Data: A limited training dataset may prompt the model to focus on patterns that do not hold true in a broader context.
Signs of Overfitting:
- High training accuracy but low validation accuracy, indicating the model performs well on the training set but poorly on new data.
- Excessive sensitivity, where minor changes in input data lead to significant shifts in predictions.
Overfitting is characterized by low bias and high variance.
Avoiding Overfitting:
Several strategies can be employed to reduce overfitting:
- Regularization: This technique limits the information captured by the model. Two common types are L1 (Lasso) and L2 (Ridge) regularization.
- Pruning (for Decision Trees): If decision trees are in use, consider pruning them to restrict their depth, preventing overly complex structures.
- Dropout (for Neural Networks): In neural networks, dropout randomly deactivates a portion of neurons during training, which helps prevent overfitting by introducing redundancy.
- Cross-Validation: Employ techniques like k-fold cross-validation to evaluate your model’s performance across various data subsets, helping to identify any overfitting issues.
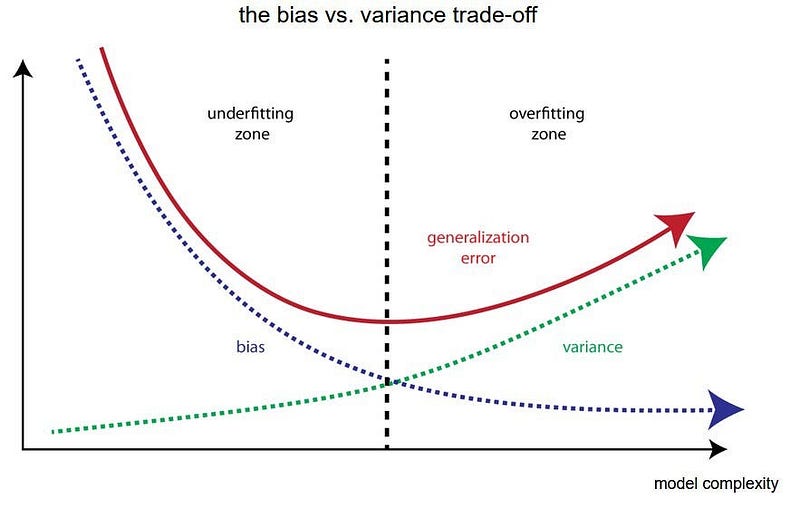
Section 1.2: Underfitting: A Different Challenge
On the other hand, underfitting occurs when a model is overly simplistic and fails to capture the essential patterns within the data. This is similar to oversimplifying a complex problem and offering inadequate solutions. An underfit model will show poor performance even on the training data.
Causes of Underfitting:
- Model Too Simple: A linear model may struggle to represent nonlinear relationships found in the data.
- Insufficient Training: Limited exposure to diverse examples can restrict the model’s ability to generalize.
Signs of Underfitting:
- Low accuracy on both training and validation datasets.
- Consistently poor predictions, regardless of input changes.
Underfitting is linked with high bias and low variance.
Avoiding Underfitting:
To counter underfitting, consider the following approaches:
- Increase Complexity: Opt for a more sophisticated model that better captures the underlying data patterns.
- Feature Engineering: Introduce new features or modify existing ones to enrich the information available to the model.
- Hyperparameter Tuning: Experiment with different hyperparameters to discover the best configuration for your model, including adjustments to learning rates and regularization parameters.
- Fine-Tune Algorithms: Test various algorithms that might be better suited to extract the underlying patterns from your specific dataset.
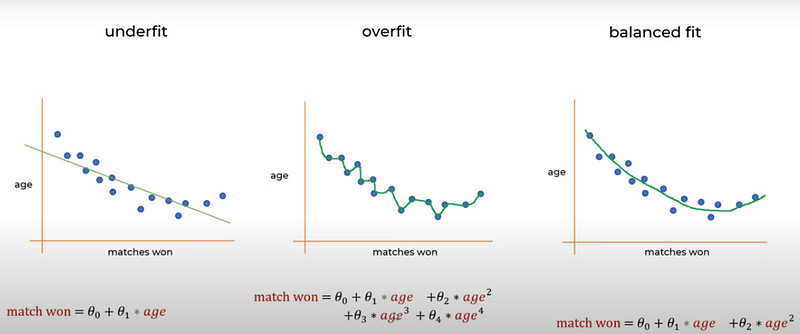
Chapter 2: Conclusion and Best Practices
In summary, addressing overfitting and underfitting represents a significant challenge in the field of machine learning. Practitioners must navigate these complexities, employing strategies like regularization, cross-validation, and careful model selection to ensure that their models generalize effectively to new data. By achieving the right balance, machine learning models can transcend mere memorization or oversimplification, providing robust solutions to intricate problems.
Thank you for taking the time to read this article! Please feel free to suggest any other topics you would like to see covered.

This video explains the concepts of overfitting and underfitting in detail, providing visual examples to enhance understanding.
In this video, the concepts of underfitting and overfitting are clarified with practical examples and solutions to these common issues in machine learning.